Million-AID: A Million Aerial Image Database for Scene Classification by Automatic Labeling

Introduction
The Million-AID dataset has 256×256 and 512×512 images, and its image resolution ranges from 0.5m-11.4m. It has three RGB spectra and is derived from multiple different remote sensing detectors. The images of the Million-AID dataset were all acquired using Google Earth. In order to make the data set more in line with the distribution of the scene in the real world, we get as much as possible global coordinate data of scene categories. In order to reflect the global distribution of images, we have calculated the geographic coordinates of all data blocks. Divide the world map into a large number of square areas, and count the number of data block coordinates falling in the square area. The following distribution map is obtained as shown in Figure 1.
The global distribution
From this histogram, it can be seen that the image resolution is mainly concentrated at 0.298m and 0.597m. This is because most of our scene categories require resolutions within 1m, so the image resolution is mainly concentrated on these two resolutions. Because different scene types need to be displayed with different resolutions, the data set contains multiple image resolutions, which also reflects the rich scene categories and large image diversity of our data set.
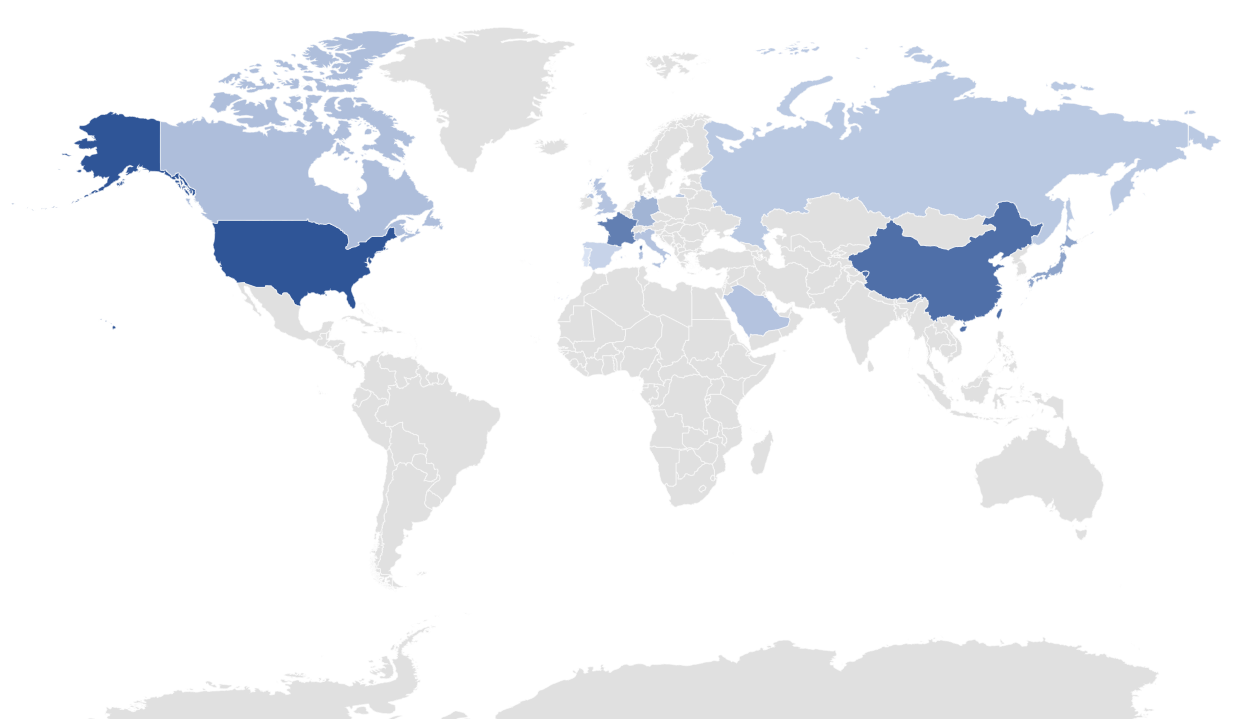
The benchmark
Here, we describe two subsets of the Million-AID database that serve as benchmarks. Million-AID-Standard and Million-AID-32.
Million-AID-Standard has 320,557 training images, including 46 scene categories, and the number of images in each category is between 4,000 and 20,000. The validation set contains 20,034 images and the test set contains 601,04 images. The experiments in this article are mainly carried out on Million-AID-Standard.
Million-AID-32 contains 32 scene categories common to NWPU and AID. Million-AID-32 is separated from Million-AID-Standard, each category contains 2000 images. Similarly, we separated the corresponding subset of 32 categories from NWPU and AID. These subsets are used to compare the image diversity between the three data sets and will be used in Section 4.3.
Download here