DesignEarth Dataset
The DesignEarth dataset is meticulously constructed to provide a comprehensive multi-modal resource for controllable aerial image generation. Overall, the dataset encompasses a vast collection of 1,326,235 images, specifically comprising 265,247 high-resolution aerial images and 1,060,988 corresponding condition images. Complementing this extensive visual data are 530,494 semantic descriptions, collectively exceeding 38.4 million tokens, ensuring rich linguistic context for each scene.
Our aerial imagery is primarily sourced from Google Earth Engine, providing a global footprint with diverse geographical and thematic coverage. The resolution of high-resolution aerial image is 1.2 meters, capturing a wide array of remote sensing scene categories, including urban landscapes, rural areas, natural environments, and industrial sites, distributed across numerous countries worldwide (as exemplified in Figure 1). To enable versatile controllable generation, each aerial image is meticulously paired with four distinct types of condition images: Map images, and Pencil Sketch, Canny, and Lineart Images. In details, map images are derived from the publicly available and highly detailed OpenStreetMap (OSM) data; the remaining three condition modalities are generated using a combination of computer graphics techniques and style transfer networks. They offer varying levels of abstract, edge-based structural information, allowing for different forms of control during image synthesis.
Figure 1: Data Distribution Across Countries
We obtain the semantic descriptions by model generation and manual refinement. For each high-resolution aerial image, we initially leverage the powerful Florence-2 model to generate two descriptions: a long caption and a short caption. Subsequently, a rigorous manual refinement process is undertaken. Human annotators meticulously modify any inaccurate or erroneous descriptive information, add missing semantic details, and enhance the overall richness and diversity of the language. This human-in-the-loop approach ensures the high quality and accuracy of the semantic descriptions, as visually illustrated in Figure 2.
Figure 2: Word Cloud Visualization
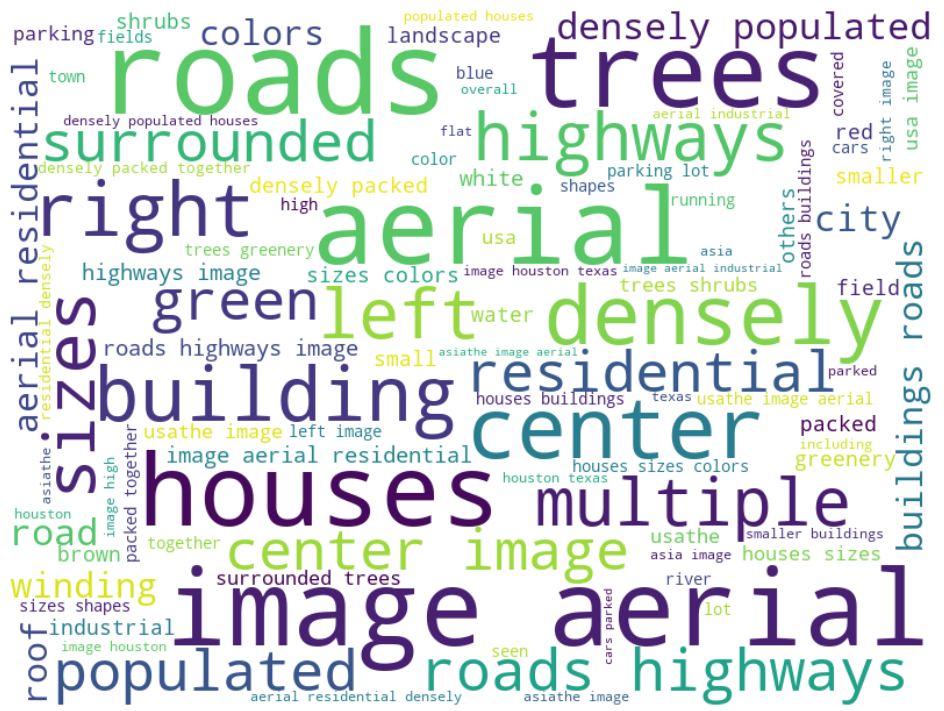
Table 1: Dataset Distribution by Cities
In summary, a single data entry within the DesignEarth dataset is a cohesive multi-modal unit designed for comprehensive scene understanding and generation. Each entry systematically includes: one high-resolution aerial image, four corresponding condition images, and two semantic descriptions. Several illustrative samples showcasing these multi-modal entries are presented in Figure 3.
Figure 3: Illustrative Samples of DesignEarth Dataset Multi-modal Entries

Benchmark
The DesignEarth dataset's multi-modal nature makes it a versatile resource applicable to a wide array of remote sensing tasks, encompassing traditional analytical challenges such as building footprint detection, semantic segmentation, scene classification, and image captioning. Given the rapid advancements in generative algorithms in recent years, our primary focus for establishing initial benchmarks on DesignEarth is on generative tasks, particularly those enabling the synthesis of complex aerial scenes. We provide two benchmarks, T2I generation and T2I controllable generation.
As a foundational generative task, we establish a benchmark for text-to-image generation, where the objective is to synthesize a high-fidelity aerial image corresponding to a given textual description. This task leverages the precisely aligned aerial images and their rich semantic descriptions within the DesignEarth dataset. To assess current capabilities, we extensively evaluated several popular and state-of-the-art generative networks, adapting them for the unique characteristics of aerial imagery. The performance of these models was quantitatively measured using a relevant metric (e.g., FID score ↓). The results for the evaluated models are summarized in Table.2
Table 2: T2I Generation Benchmark
Table 3: T2I Controllable Generation Benchmark
Beyond pure text-to-image synthesis, a core objective of DesignEarth is to facilitate controllable aerial image generation. For this benchmark, models are tasked with generating aerial images conditioned on both a textual prompt and various control images. These control images, including maps, pencil sketches, Canny edge maps, and lineart representations. We evaluated several cutting-edge controllable generative networks, adapting them to leverage DesignEarth's multi-modal inputs. The performance metrics (e.g., FID score ↓) for these models across different control modalities are presented in the Table.3. The visalized results are shown in the Figure.4.
Figure 4: Controllable Generation Results
Hover over the control images to see the generated aerial images
Map
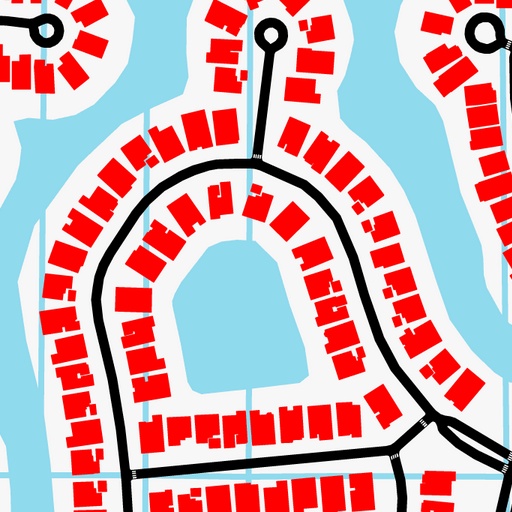

"An aerial view of a residential area with circular layouts and surrounding roads and scattered houses surrounded by green vegetation and a river."
Pencil
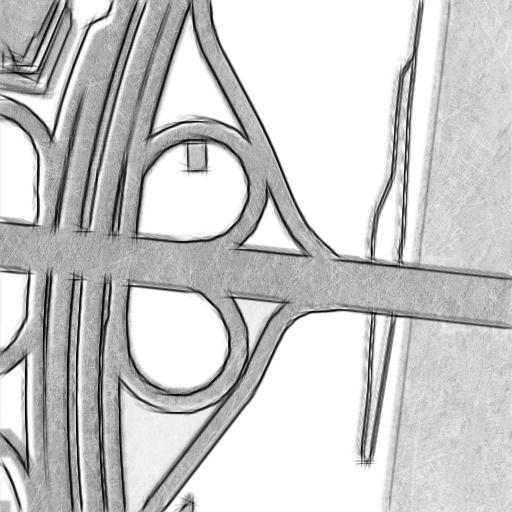

"A top-down view of a highway intersection with multiple lanes, overpasses. The roads are surrounded by trees and shrubs, there is a large building on the left."
Canny
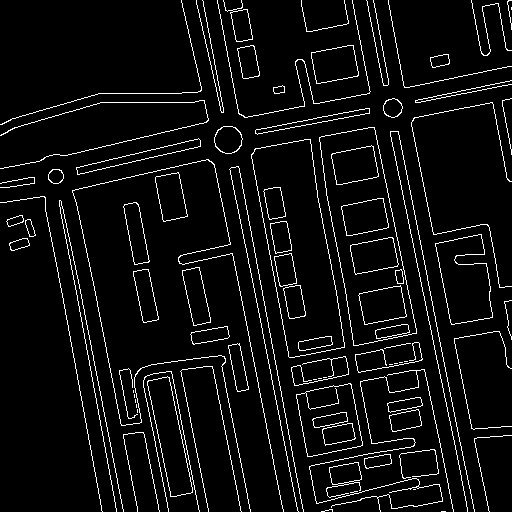

"An aerial photograph showing a large industrial area in the desert. There are multiple buildings, roads, and several parking spaces with cars parked in them."
Lineart
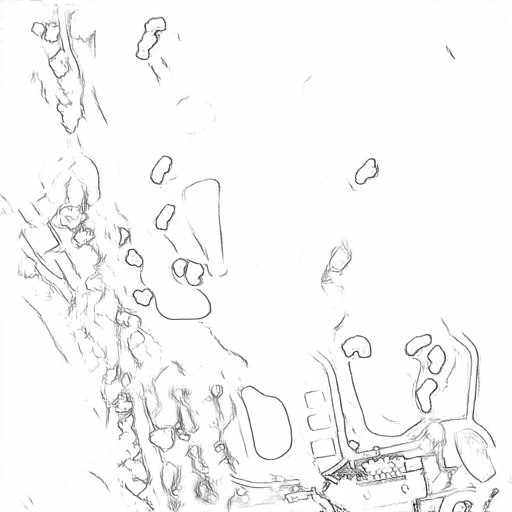

"A satellite view of a golf course surrounded by green fields and trees. Several fairways and bunkers are scattered throughout the course with a few buildings and roads."