CondRef-AR: Condition-as-a-Reference Randomized Autoregressive Modelling for Controllable Aerial Image Generation
Pu Jin
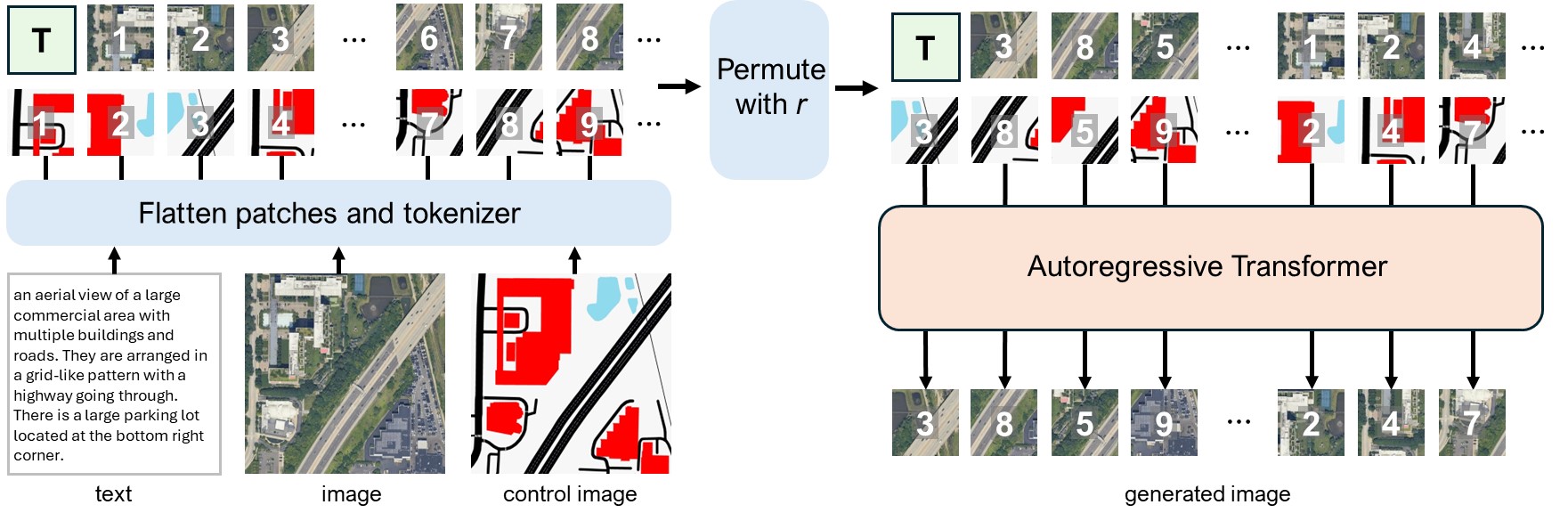
Controllable image generation, particularly for complex aerial scenes, demands both high-fidelity synthesis and precise adherence to input conditions such as semantic maps or edge diagrams. Aerial imagery is characterized by extensive spatial dependencies, where geographical features and objects exhibit strong correlations across the entire scene. Accurately modeling these long-range interactions often requires a broader contextual field of view to capture comprehensive spatial relationships. Recently, autoregressive (AR) models make significant progress in controllable generation. However, their inherent unidirectional context modeling limits the global coherence and structural fidelity of generated images. To overcome this constraint, we propose ConRef-AR, a novel Condition-as-a-Reference randomized autoregressive modelling for controllable aerial image generation. Our approach is built upon a key insight: in controllable tasks, the input condition is not merely a static guide but a dynamic, intrinsic reference that specifies the content for each spatial location. To leverage this, CondRef-AR employs a randomized training strategy where the image token sequence is permuted during training to expose the model to diverse contexts. Crucially, instead of relying on auxiliary mechanisms to resolve prediction ambiguities introduced by randomization, our core innovation is to directly utilize the corresponding control signal as the primary reference for predicting each token. This elegant substitution allows the model to naturally disambiguate predictions while simultaneously achieving superior control precision, thereby enhancing both generation quality and fidelity within the efficient autoregressive paradigm.